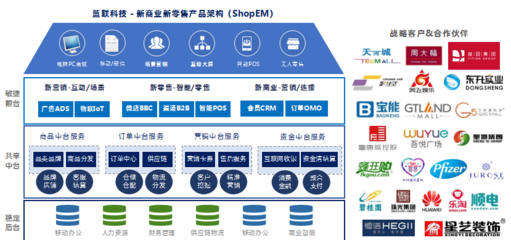
在信息技術應用創新(信創)浪潮中,企業面臨著技術升級、系統兼容、人才儲備等多重挑戰。互軟信創適配中心憑借深厚的行業經驗和技術積累,為客戶提供適配、認證、咨詢、培訓四位一體的全方位信創技術服務,結合軟件研發及技術支持,助力企業實現平滑、高效的數字化轉型。
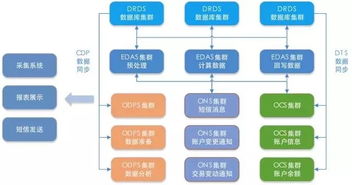
適配服務是互軟信創適配中心的核心優勢之一。我們針對不同硬件平臺、操作系統和數據庫環境,進行軟件系統的全面適配測試與優化,確保系統在信創生態下穩定運行。無論是國產CPU、操作系統,還是云環境部署,我們都能提供定制化的適配解決方案,幫助企業降低遷移風險,提升系統兼容性。
認證服務為企業提供權威的技術背書。互軟信創適配中心與多家信創生態伙伴合作,協助客戶完成產品兼容性認證、安全認證等流程。通過我們的專業指導,企業能夠快速獲得行業認可,增強市場競爭力,并為后續業務拓展奠定基礎。
咨詢和培訓服務則從戰略和人才層面支持企業信創轉型。我們的咨詢團隊基于客戶實際需求,提供從規劃、實施到運維的全生命周期建議,幫助企業制定合理的信創路線圖。培訓服務涵蓋技術實操、政策解讀和最佳實踐分享,通過線上線下結合的方式,提升團隊技能水平,確保企業能夠自主應對信創環境下的技術挑戰。
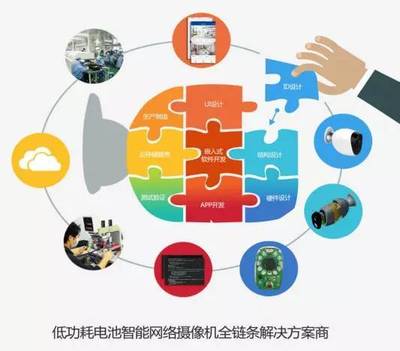
互軟信創適配中心還專注于軟件研發及技術服務。我們擁有一支經驗豐富的研發團隊,能夠根據客戶需求定制開發信創兼容的軟件系統,并提供持續的技術支持與升級服務。無論是現有系統改造還是全新項目開發,我們都能確保高質量交付,助力企業在信創浪潮中搶占先機。
互軟信創適配中心以適配、認證、咨詢、培訓為核心,結合軟件研發及技術服務,為企業提供一站式信創解決方案。在數字化轉型的關鍵時期,我們愿與您攜手共進,共創信創未來。